
Par Alexandre Lepage, Directeur principal, Entreprise numérique
Œuvrer en services-conseils en technologie de l’information ne permet pas nécessairement de développer des aptitudes techniques applicables dans notre vie à l’extérieur du travail. À titre d’exemple – et je suis certain que plusieurs s’y reconnaîtront – pour la famille et bien des proches, notre carrière fait de nous au mieux une sorte de « help desk » bénévole, sans pour autant que ce soit là notre expertise. Eh bien, laissez-moi vous raconter une (més-)aventure personnelle récente – j’en suis le seul et unique artisan : bien fait pour moi! – qui aura fait appel justement à mes quelques décennies d’expérience professionnelle.
De Windows 10 vers macOS
J’écrivais dans un précédent article que j’étais devenu un développeur Microsoft complet sur un MacBook Pro. Comme tel, ce scénario étonnera peut-être encore quelques dinosaures, mais ce serait oublier que depuis la grande transition d’Apple vers Intel il y a plus de 15 ans, rouler un OS Windows sur un Mac, par l’entremise de Boot Camp par exemple n’est pas un exploit en soi. Mais ce n’est pas ce dont il s’agit ici : je parle bel et bien de développer avec les technologies dites de Microsoft à même un OS d’Apple, macOS Mojave dans mon cas.
Comme l’objectif de cet article n’est pas de documenter les diverses manières de configurer un MacBook à des fins de développement Microsoft – les sources à cet effet pullulent sur le Web – je me contenterai de n’écrire ici que les grandes lignes de ma transition Windows 10 vers macOS Mojave :
· Installation et emploi récurent du gestionnaire de packages Homebrew: gérer l’installation et la mise à jour des outils et applications que j’emploie à l’aide de cet utilitaire est for me, for me, formidable …;
· Mettre à jour Bash et l’employer pour à peu près tout : retourner à un vrai terminal – MS-DOS quelqu’un? – et passer le clair de mon temps à écrire des commandes plutôt que cliquer sur des icônes est un vœu que je souhaitais exaucer depuis mes années Unix – IRIX pour être précis – dans un autre millénaire;
· Installer le kit de développement .NET Core ainsi que ma licence de l’IDE intégré Rider de JetBrains: dans mon cas, développeur Microsoft complet veut en particulier dire développement applicatif, idéalement autrement que par l’entremise de Visual Studio;
· Installer l’engin de virtualisation Docker – disons – puis y charger l’image officielle de SQL Server 2017: pour moi, développeur Microsoft complet veut également dire développement de solutions analytiques, et que SQL Server 2017, malgré son support Linux, ne s’installe pas nativement sur macOS, du simple fait que le kernel macOS est XNU, ou X is Not Unix, pas tout à fait Linux.
Sur ce dernier point, j’admets ici que malgré mes motivations, je n’ai pas pu faire autrement que d’installer l’engin de virtualisation Parallels et de configurer tout de même une lourde machine virtuelle Windows 10 munie de Visual Studio pour la prise en charge de composants de certaines https://www.virtualbox.org/solutions analytiques : les projets de type base de données SQL, SSIS, SSAS, SQL Services et SSRS, pour ne nommer que ceux-ci. Pour le reste, il y a Amazon Web Services, Google Cloud, Microsoft Azure et … Mastercard! Je suis ravi de la configuration de mon poste de travail, le charme opère toujours après 3 ans et, à dire vrai, je ne reviendrai pas en arrière, du moins, tant que Windows ne sera pas bâti autour d’un kernel Linux ou équivalent.
Cela dit je n’emploie pas mon Mac uniquement comme poste de travail – c’est mon Mac, je l’ai payé avec mes sous, oh et puis c’est ma vie et je fais ce que je veux! – et là où je me suis un peu plus amusé – c’est définitivement un euphémisme – c’est avec l’emploi initial d’un logiciel on ne peut plus Apple: iTunes.
Mélomane à l’ère numérique
Je mentionnais également dans S(QL)imulation Theory être un fan fini de Muse: c’est tout à fait vrai! Mais la musique de Matt Bellamy et. al. n’est pas la seule que j’écoute, loin de là. Je possède toujours des milliers de CD et une petite centaine de vinyles pour les moments d’écoute concentrée, mais, comme plusieurs, mon principal mode de consommation musicale étant mon iPhone – iPod à l’époque – je me suis bâti au cours des 15 dernières années une volumineuse librairie de quelques 30,000 fichiers musicaux – tous légitimes je vous l’assure – toujours gérés par l’entremise d’iTunes.
Jusqu’à ma conversion à R’hllor, j’employais iTunes sur un PC Windows donné, mais comme ma librairie musicale est rigoureusement organisée – ceux qui me connaissent bien vont sourire ici – et est en réalité stockée sur un NAS ou Network Attached Storage, j’envisageais un passage de iTunes Windows vers iTunes macOS selon un processus des plus simples:
· Faire pointer iTunes macOS sur mon NAS pour qu’il reconstruise sa librairie;
· Exporter mes nombreuses listes de lecture d’iTunes Windows sur mon ancien PC puis les importer dans iTunes macOS à l’aide de fonctionnalités natives;
· M’assourdir à grands coups de décibels.
Et comme c’était déjà ce que je faisais depuis longtemps sur iTunes Windows, m’assurer au préalable d’avoir activé l’option « Laisser iTunes organiser le dossier iTunes Media » avant de procéder. Grave erreur: cette transformation numérique ne se ferait pas sans heurt!
iTunes et son organisation
L’option « Laisser iTunes organiser le dossier iTunes Media » résulte en une nomenclature et une arborescence qui va comme suit :
|_ racine du répertoire media
|_ premier répertoire selon nommé nom de l’artiste
|_ second répertoire nommé nom de l’album
|_ fichier musical nommé numéro de piste␣nom de piste.extension
Par exemple :
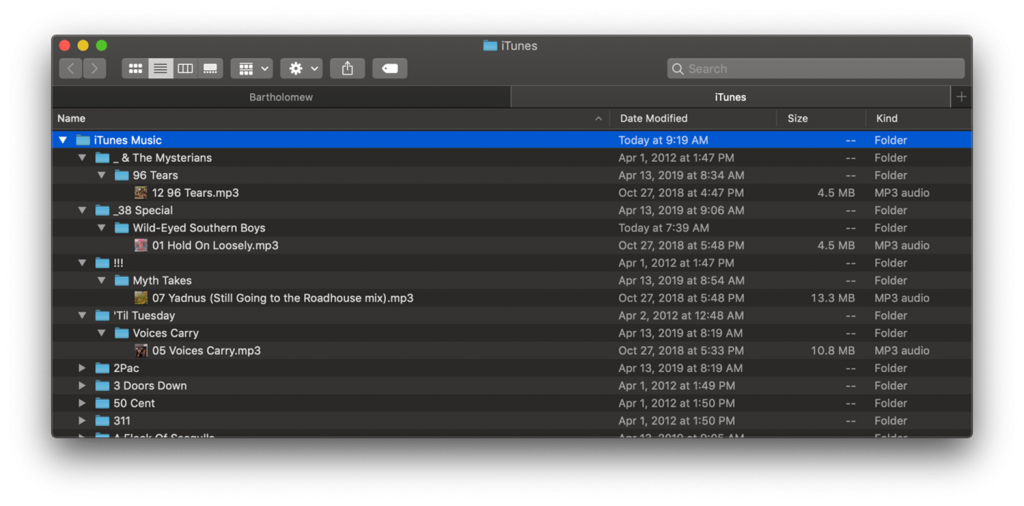
Comme mes fichiers musicaux suivaient déjà une telle convention, quelle ne fut pas ma surprise lorsque je réalisai – au passé simple SVP – une fois le processus lancé, qu’iTunes macOS renommait progressivement des centaines et des centaines de fichiers en bâtissant sa nouvelle librairie! Pourquoi?
Mis à part quelques rares cas qui ne respectaient pas la convention ci-dessus, 3 raisons principales ont expliqué cette réécriture de fichiers :
- Pour des pistes achetées chez Apple, iTunes semble favoriser les métadonnées du magasin et renverser certaines modifications que j’avais patiemment appliquées au cours des années: par exemple, l’album «The Girl with The Dragoon Tattoo» a été renommé «The Girl with the Dragon Tattoo (Original Soundtrack)»;
- Contrairement à Windows par défaut, le système de fichiers de macOS est sensible aux majuscules et minuscules: petit oubli de ma part;
- iTunes Windows et iTunes macOS n’encodent pas toujours les lettres accentuées dans le référentiel de la même manière : par exemple, un simple « é » est représenté dans la forme composée %C3%A9 – le caractère unique U+C3A9 – du côté Gates, dans la forme décomposée e%CC%81 – les deux caractères U+0065 U+0301 – du côté Jobs.
Qu’iTunes macOS renomme ainsi certains répertoires et fichiers n’était pas un problème quant à la reconstruction de sa librairie. Par contre, ma stratégie d’exportation/importation de listes musicales tombait à l’eau: en aucun cas iTunes ne pouvait recréer la bonne référence d’un fichier musical déplacé lors de l’importation d’une liste de lecture donnée.
L’appariement flou
Évidemment, j’aurais pu restaurer une copie de sauvegarde de mes fichiers musicaux et procéder différemment. Mais cela aurait été trop facile et je n’aurais rien eu à écrire à ce sujet. Et recréer manuellement mes listes de lecture était hors de question: on parle ici d’une centaine de listes, l’une d’entre elles contenant en particulier 1001 pistes! Mais puisque j’ai consacré une bonne partie des 20 dernières années à intégrer des données dans diverses structures analytiques, je me suis demandé si je ne pouvais pas appliquer une telle expertise à la résolution de mon problème.
Comme l’exportation d’une liste de lecture produit un fichier XML, ma question initiale était: puis-je programmatiquement traiter ce fichier XML pour y substituer le nom d’un fichier musical tel que produit par l’exportation iTunes Windows par le nom attendu par l’importation iTunes macOS?
Pour que ce soit clair, voici un exemple très réel de fichier musical renommé par le processus et tel que contenu dans une liste de lecture donnée :
Tel que produit par l’exportation iTunes Windows:
Benjamin%20Biolay/La%20superbe/05%20Ton%20h%C3%A9ritage.m4a
Tel qu’attendu par l’importation iTunes macOS:
Benjamin%20Biolay/La%20superbe%20%28Deluxe%20Version%29/05%20Ton%20he%CC%81ritage.m4a
(j’ai volontairement omis dans cet exemple les racines des répertoires média : bien que distinctes entre iTunes Windows et iTunes macOS, elles étaient respectivement constantes et pouvaient être facilement ignorées.)
Comment alors arrimer des chaînes de caractères à la fois si semblables et si différentes l’une de l’autre? Mais n’est-ce pas ici un problème classique en couplage de dossiers? Puis-je alors employer des techniques d’appariement flou – il semblerait que ce soit ici la traduction française de fuzzy matching – pour m’aider à le régler? Si oui, quel est mon angle d’approche technologique:
- chargement des listes de lecture en format XML dans une base de données SQL Server puis manipulation avec T-SQL?
- traitement complet par l’entremise d’un package SSIS?
- autre option?
Python à la rescousse
L’approche T-SQL me paraissait un peu trop alambiquée pour résoudre efficacement mon problème et le développement SSIS semblait pointer vers l’utilisation de la transformation Fuzzy Lookup qui ne m’a jamais emballée. J’ai alors décidé d’écrire un petit script Python pour convertir une liste musicale exportée par iTunes Windows en une liste musicale importable par iTunes macOS. Il est plutôt efficace et n’a qu’une soixantaine de lignes grâce à l’emploi de quelques librairies et modules plutôt chouettes :
- lxml: manipulations XML;
- os : navigation et manipulations dans le système de fichiers;
- jellyfish : arrimage phonétique ou approximatif de chaînes de caractères.
Comme mon script complet est disponible sur GitHub, je ne reproduirai ici que ses principaux blocs:
Boucle principale
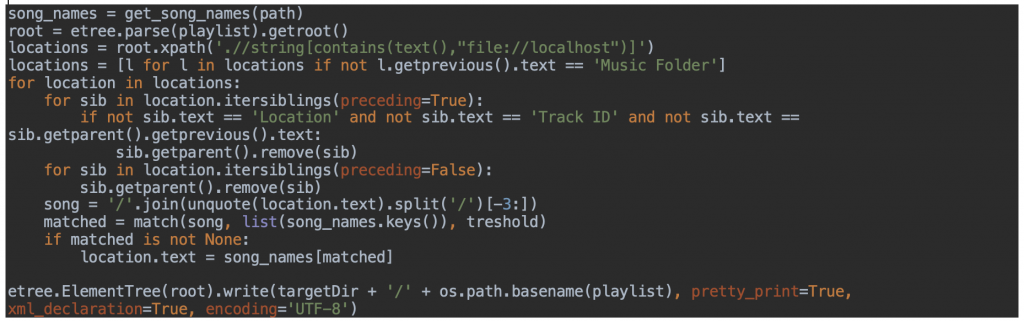
En gros:
- Initialisation de la liste de fichiers musicaux par navigation dans le système de fichiers (voir plus loin);
- Initialisation d’un objet XML correspondant à une liste de lecture donnée telle qu’exportée par iTunes Windows;
- Identification des éléments représentant une piste : notons au passage que le format XML employé par iTunes lors de l’exportation d’une liste de lecture n’est pas particulièrement convivial et qu’un peu de rétro-ingénierie a été nécessaire;
- Appariement flou de chaque piste avec au mieux un fichier musical dans la liste initialisée plus tôt (voir plus loin);
- Substitution dans l’objet XML en cas de succès;
- Sauvegarde de l’objet XML dans une nouvelle liste de lecture importable par iTunes macOS.
Initialisation de la liste de fichiers musicaux

La fonction ci-dessus fabrique un dictionnaire – une collection de paires « clé-valeur » – à partir des fichiers musicaux trouvés récursivement à partir d’un répertoire donné :
- Clé: chaîne de caractères affranchie de quelques particularités d’encodage des lettres accentuées et représentant la combinaison nom de l’artiste/nom de l’album/numéro de piste␣nom de piste.extension
- Valeur : localisation exacte du fichier musical correspondant, selon le format attendu par l’importation iTunes macOS.
Appariement flou

C’est avec cette fonction que la magie opère:
- Elle reçoit 4 paramètres:
- x: chaîne de caractère source cherchée;
- y : liste de chaînes de caractères qui contient x, quelque chose de proche à x ou rien de tout ça;
- treshold: seuil de similarité pour qu’une chaîne de caractères dans y soit considérée comme proche à x; une similarité à 0 signifie deux chaînes de caractères complètement différentes l’une de l’autre;
- limit: plafond de similarité pour qu’une chaîne de caractères dans y soit considérée comme la plus proche possible de x; une similarité de 1 signifie deux chaînes de caractères identiques;
- Elle cherchera successivement dans la liste y la chaîne de caractères jugée la plus similaire à x et la retournera si elle existe.
Pour reprendre l’exemple plus haut :
- x = ‘Benjamin Biolay/La superbe/05 Ton héritage.m4a’
- y = […, ‘Benjamin Biolay/La superbe (Deluxe Version)/05 Ton héritage.m4a’, …]
- treshold = 0.85 (une similarité d’au moins 85% me semble adéquate)
- limit = 1 (en principe, une similarité de 100% signifie un arrimage parfait)
Et on souhaite que la fonction retourne ‘Benjamin Biolay/La superbe (Deluxe Version)/05 Ton héritage.m4a’, ce qui est bien le cas.
Comment fonctionne le tout?
Distance entre deux chaînes de caractères
L’essentiel de l’appariement flou se base sur une idée de proximité textuelle – si vous avez lu promiscuité sexuelle, vous n’êtes pas à la bonne tribune – entre deux chaînes de caractères. Dit autrement, une certaine notion de distance. À cet effet, la librairie Python jellyfish offre quelques méthodes dignes de mention:
levenshtein_distance
La distance de Levenshtein entre deux chaînes de caractères est déterminée par le nombre d’éditions unitaires (insertions, suppressions ou substitutions) requises pour passer d’une chaîne à l’autre. Par exemple:
- La distance de Levenshtein entre ‘Alexandre’ et ‘Alexander’ est 2. On supprime le ‘r’ et on en insère un à la fin;
- Entre ‘Benjamin Biolay/La superbe/05 Ton héritage.m4a’ et ‘Benjamin Biolay/La superbe (Deluxe Version)/05 Ton héritage.m4a’, elle est 17. Faites l’exercice!
Plus cette distance sera petite, plus les chaînes de caractères seront jugées « proches » ou similaires. La distance de Levenshtein supporte régulièrement des technologies comme les correcteurs orthographiques et est employée par certains algorithmes de reconnaissance textuelle.
damerau_levenshtein_distance
La distance de Demareau-Levenshtein est essentiellement une variante de la distance précédente qui considère également la transposition entre deux caractères adjacents comme une édition unitaire. Par exemple:
- La distance de Demareau-Levenshtein entre ‘Alexandre’ et ‘Alexander’ est 1 : on permute simplement les ‘r’ et ‘e’ de la fin;
- Entre ‘Benjamin Biolay/La superbe/05 Ton héritage.m4a’ et ‘Benjamin Biolay/La superbe (Deluxe Version)/05 Ton héritage.m4a’, elle est 17.
hamming_distance
A priori, la distance de Hamming entre deux chaînes de caractères d’une même longueur est déterminée par le nombre de positions occupées par des caractères différents. Par exemple:
- La distance de Hamming entre ‘Alexandre’ et ‘Alexander’ est 2. Les positions 8 et 9 sont occupées par des caractères différents.
Cette distance se généralise à des chaînes de caractères de longueurs différentes en comptant également toutes les positions supplémentaires de la chaîne la plus longue. Par exemple:
- La distance de Hamming entre ‘Benjamin Biolay/La superbe/05 Ton héritage.m4a’ et ‘Benjamin Biolay/La superbe (Deluxe Version)/05 Ton héritage.m4a’ est 37. Toutes les positions passées ‘superbe’ sont occupées par des caractères différents.
La distance de Hamming, plutôt technique, est employée par exemple en télécommunications pour compter le nombre de bits retournés ou en systématique pour calculer la « distance génétique ». Merci Wikipédia.
jaro_distance
Prêts pour le volet hardcore de cet article? La similarité de Jaro entre deux chaînes de caractères et est déterminée par la formule mathématique suivante:
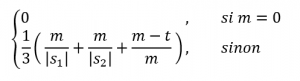
où :
- |s1|et |s2| sont les longueurs respectives des chaînes s1 et s2
- m est le nombre de caractères arrimés, c’est-à-dire qui sont les mêmes dans les chaînes et qu’ils ne sont pas plus éloignés que
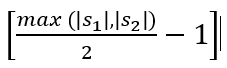
- t est la moitié du nombre de transitions, c’est-à-dire le nombre de caractères arrimés, mais se trouvant en des positions différentes, divisé par 2.
Des volontaires pour me programmer tout ça de manière performante? Il faut remarquer que la formule ci-dessus parle bien de similarité, pas de distance. La distance de Jaro est bêtement 1 moins le résultat de cette formule, mais la similarité demeure une mesure plus pratique dans notre contexte:
- Plus la similarité sera proche de 1, ou de 100% selon l’échelle, plus les chaînes de caractères seront jugées semblables;
- À l’opposé, plus la similarité sera proche de 0, plus les chaînes de caractères seront considérées distinctes.
Par exemple:
- La similarité de Jaro entre ‘Alexandre’ et ‘Alexander’ est 0.963;
- Entre ‘Benjamin Biolay/La superbe/05 Ton héritage.m4a’ et ‘Benjamin Biolay/La superbe (Deluxe Version)/05 Ton héritage.m4a’, elle est 0.859.
jaro_winkler
La similarité de Jaro-Winkler entre deux chaînes de caractères est essentiellement une variante de la similarité précédente qui bonifiera les chaînes de caractères qui commencent par les mêmes préfixes. Par exemple:
- La similarité de Jaro-Winkler entre ‘Alexandre’ et ‘Alexander’ est 0.978;
- Entre ‘Benjamin Biolay/La superbe/05 Ton héritage.m4a’ et ‘Benjamin Biolay/La superbe (Deluxe Version)/05 Ton héritage.m4a’, elle est 0.916.
Les valeurs en exemple ne sont pas pertinentes en soi, mais constatez que, dans les deux cas, la similarité de Jaro-Winkler produit des valeurs plus élevées que la similarité de Jaro.
Intéressant, ce favoritisme pour des chaînes de caractères qui commencent de la même manière. Ma situation regorge de cas où iTunes macOS s’est cru obligé de rajouter des suffixes à la « édition fantastico-extraordinaire » aux noms originaux exportés. Et puisque j’ai très peu de fichiers musicaux d’artistes dont les noms ou prénoms commencent par une lettre accentuée…
Non, ma librairie ne contient pas l’intégrale Étienne Charry … je tue, je tue le temps ?? en t’a, en t’attendant ?? …
Résultats
Grâce à mon script Python et le choix éclairé d’une fonction d’appariement flou basée sur la similarité de Jaro-Winkler, j’ai pu convertir ma centaine de listes musicales exportées par iTunes Windows dans le format attendu par l’importation iTunes macOS. Du point de vue de la précision des résultats, une dizaine de pistes sur à peu près 3,000 pistes distinctes dans les diverses listes n’ont pas pu être arrimées automatiquement par mon script. Et cela, presque exclusivement en raison de mon seuil de similarité que j’imposais à 0.85. Par exemple:
- La similarité de Jaro-Winkler entre ‘Mötley Crüe/Shout At The Devil/08 Too Young To Fall In Love.mp3’ et ‘Mötley Crüe/Shout At The Devil/08 Too Young To Fall In Love.mp3’, n’est que 0.844.
On ne juge pas des goûts. L’œil aiguisé aura remarqué qu’il s’agit des mêmes chaînes de caractères dans cet exemple, le lecteur attentif répondra que les chaînes comparées sont en réalité:
‘M%C3%B6tley%20Cr%C3%BCe/Shout%20At%20The%20Devil/08%20Too%20Young%20To%20Fall%20In%20Love.mp3’
et
‘Mo%CC%88tley%20Cru%CC%88e/Shout%20At%20The%20Devil/08%20Too%20Young%20To%20Fall%20In%20Love.mp3’
Limite d’affichage dans mon article.
Avec un taux de succès de 99.7%, je conclus que mon script a constitué une solution viable à mon problème. Je peux maintenant m’assourdir en paix!
Conclusion
Grosse introduction pour finalement discuter d’appariement flou! Évidemment, ma réelle intention n’est pas de réutiliser mon script Python pour de futurs arrimages de listes de lectures.. C’est fait et on n’en parle plus! Mon intérêt est plutôt d’utiliser davantage de méthodes et techniques semblables – avec ou sans Python – dans l’élaboration de pipelines d’intégration de données: l’harmonisation de données disparates demeure une variable importante dans la grande équation de l’ingénierie de données et si elle peut se faire sans règles de transformation alambiquées ou gestion d’exceptions, le monde s’en portera mieux!
Qu’en pensez-vous?