
Par Maxime Fargeot, Conseiller principal, Analytique des données
Snowflake offre de nombreuses fonctionnalités intéressantes, mais aujourd’hui, je me dois de parler de l’une d’entre elles qui me semble incontournable, tellement elle facilite la vie: les Table Streams ou flux de table.
Connaissez-vous les TABLE STREAMS ?
Un Stream est un objet Snowflake qui permet de détecter et capturer tous les changements de données d’une table pour pouvoir ensuite les exploiter.
Ce type de technologie est communément appelée « Change Data Capture ». Bien que cela existe chez d’autres éditeurs, l’implémentation proposée par Snowflake est très intéressante grâce à sa simplicité d’utilisation et son faible coût.
Comment ça marche ?
Imaginons une table contenant diverses données qui changent au cours du temps avec des ajouts, des modifications ou des suppressions. Créer un Stream équivaut à créer un point de sauvegarde de l’état de cette table à un instant T, puis prendre en considération les différents changements qui s’y produisent.
La documentation Snowflake donne l’image d’un livre (la table) dans laquelle on placerait des marque-pages (Offset d’un Stream). Les données de la table ne sont pas dupliquées dans les Streams, il faut plutôt le voir comme des pointeurs. Cela veut dire qu’un n’augmentera pas les coûts de stockage de manière significative.
Pour illustrer la création d’un Stream, on pourrait imaginer observer une scène avec une caméra et décider à un certain moment de démarrer l’enregistrement (même si encore une fois, un Stream n’enregistre pas réellement de donnée).
De la même façon que plusieurs caméramans filment une scène, il est possible de créer plusieurs Streams sur une même table . À noter que chaque cameraman peut décider de démarrer l’enregistrement quand il le souhaite. Donc même si le sujet est le même, l’histoire du film peut être différente.
Astuce : Un Stream sera par défaut créé sur la dernière version des données de la table. Il est toutefois possible de le combiner avec le « Time Travel » (cette fonction permettant d’accéder à des versions historiques de données) pour aller se positionner dans le passé. Il ne sera toutefois pas permis de remonter en deçà du moment où le Change Tracking a été activé.
Cette illustration, volontairement simplifiée, présente le cycle de vie d’une table et de deux Streams créés à différents moments .
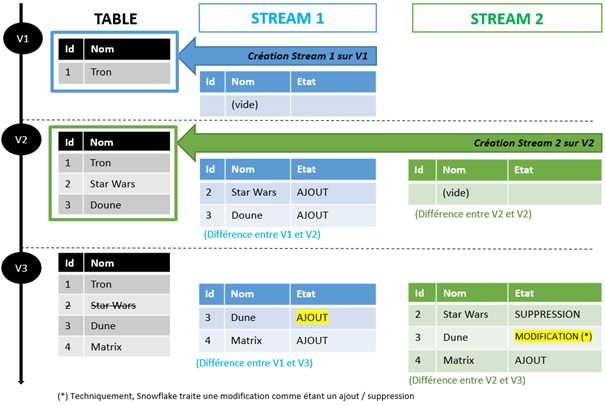
Stream 1 et Stream 2 ont été créés sur le même sujet. Pourtant, on constate que leur contenu peut différer en fonction de quand ils ont été créés.
Faisons une comparaison entre ces deux Streams :

Stream 2 contient même plus de lignes que Stream 1 à la fin. La raison ? Il y a plus de différences entre la V2 et V3 de la table, qu’entre sa V1 et V3.
Comme Stream 1 et Stream 2 ont deux points de vue différents, il est normal que ce que remonte chaque Stream soit différent. De la même façon, deux Streams qui pointent vers la même version (Offset) de la table auront obligatoirement un contenu identique.
Astuce : Par défaut, un Stream va traquer toutes les opérations DML réalisées sur la table source. Il existe toutefois une option pour ne traquer que les insertions : « Append-only » (tables classiques) / « Insert-only » (tables externes, ces vues optimisées sur des fichiers). De plus, pour les tables externes, seul le mode « Insert-only » est supporté.
Consommation d’un Stream
Un Stream se lit à la manière d’une table. Toutefois il se « vide » automatiquement une fois consommé par une instruction DML telle qu’un INSERT, UPDATE, DELETE… Celui-ci ne remonte alors plus aucune ligne. Ou plutôt, il ne remonte plus aucune différence ! Car son point de référence a été réinitialisé : c’est à nouveau la dernière version de la table.
On peut aussi considérer qu’à chaque fois qu’il est consommé, c’est un peu comme si on recréait un nouveau Stream (toutes les différences passées sont « oubliées »).
Tant qu’un Stream n’est pas consommé, il va continuer d’accumuler des différences depuis son dernier point de référence. Toutefois, il existe une limite de temps au-delà de laquelle celui-ci peut se trouver être en état corrompu (Stale).
Astuce : Pour consommer un même Stream avec plusieurs instructions DML, il suffit d’entourer ces instructions d’une transaction. Le jeu de données du Stream ne disparaitra pas tant que la transaction n’est pas validée. On préfèrera cependant créer plusieurs Streams sur une même table si ces processus n’ont rien avoir entre eux.
Une fois ces concepts compris, voyons comment cela a été concrètement implémenté dans Snowflake.
Implémentation concrète et métadonnées du Stream
Lors de la création d’un Stream, celui-ci comporte les mêmes champs que la table source au moment de sa création ainsi que trois champs de métadonnées additionnels indispensables :
- METADATA$ROW_ID : Contient l’identifiant interne unique de la ligne qui est traquée.
- METADATA$ACTION : Peut prendre deux valeurs « INSERT » ou bien « DELETE ».
- METADATA$ISUPDATE : Passe à « TRUE » pour gérer l’état de modification (UPDATE).
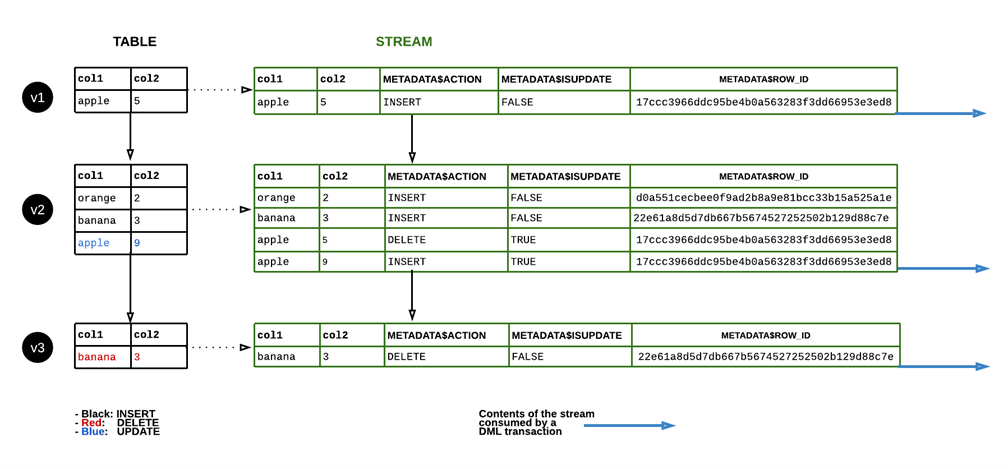
Cas de figure possibles dans la table source :

Astuce : L’opération TRUNCATE TABLE passera toutes les lignes du Stream en statut DELETED. Cela ne videra pas le Stream. Ainsi, il reste consistant.
Même l’ajout et la suppression d’une colonne sont pris en compte automatiquement.
- Lorsqu’une colonne est ajoutée, le Stream crée aussi une nouvelle colonne dont la valeur sera la valeur par défaut de la colonne dans la table source.
- Lorsqu’une colonne est supprimée, le Stream supprime la colonne.
- Les changements de types effectués sur la table Source sont aussi reportés, si naturellement ceux-ci sont permis.
Maintenant, dans quels cas peuvent être utilisés les tables Stream ?
Comment est-ce mis en application ?
Les Streams peuvent être utilisés dans des scénarios de chargements en lots ou bien de mise à jour en temps réel.
On pourrait par exemple imaginer un processus avec Snowpipe qui intègre des fichiers en flux continu. Un Stream récupère automatiquement ces nouvelles données. Pour finir, une Task tourne régulièrement pour consommer le Stream et faire des transformations.
Par extension, dans le domaine de l’informatique décisionnelle, ce type de système peut servir à mettre en place très simplement et efficacement une dimension à évolution lente (« Slowly Changing Dimension ») de type 2 par exemple.
Les Streams offrent donc de très belles possibilités, surtout quand ils sont combinés avec d’autres fonctionnalités natives de Snowflake telles que le TimeTravel, les Tasks et Snowpipe .



