
Par Gaël Baudry, Conseiller, Analytiques des données
Snowflake est une solution « entrepôt de données infonuagique » en mode SaaS. Elle se distingue par une grande simplicité à travers plusieurs aspects, que ce soit au niveau de son interface épurée ou de la mise en place de la scalabilité et de l’élasticité avec son architecture unique. On parle également de DWaaS (Datawarehouse as a service), un service pour lequel le prestataire s’occupe de la configuration, du hardware et du software, de l’optimisation et de la maintenance. Ainsi délesté de ces contraintes, le client met l’accent sur ses données et a alors toute la latitude pour les traduire efficacement en valeur.Il peut alors se concentrer sur l’alimentation de l’entrepôt et la production d‘analyses, accélérant ainsi sa productivité.
Une interface simple et épurée
Le premier contact avec Snowflake laisse entrevoir son interface accessible. Il s’agit de mettre en avant un ensemble contenu de fonctionnalités représentées par des onglets.
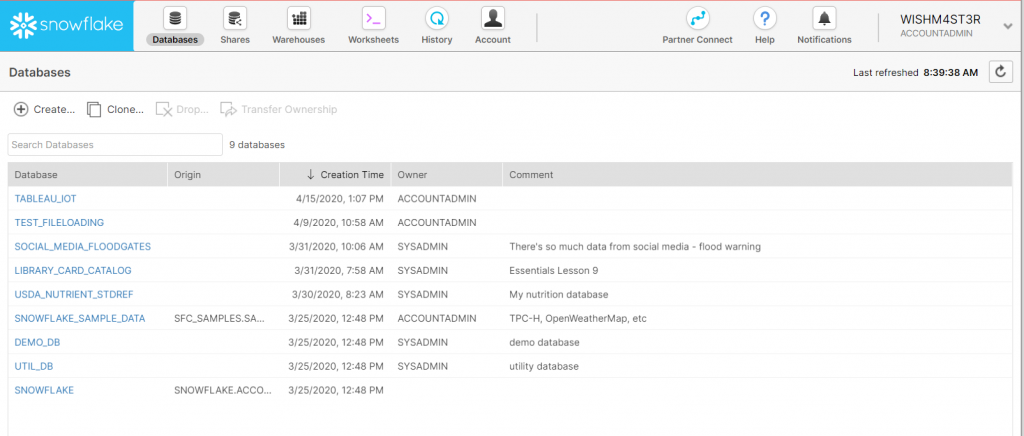
Ces différents onglets vont à l’essentiel : alors que Databases permet de naviguer à travers les objets des bases de données hébergées dans Snowflake (tables, vues, schémas, etc…), Shares permet la gestion du partage des données, Warehouses permet quant à lui de gérer les entrepôts virtuels, les unités computationnelles de Snowflake, responsable de l’exécution des requêtes et des diverses tâches de chargement. L’onglet Worksheets donne accès aux commandes SQL (qui seront exécutées par les fameux warehouse), alors que l’onglet History autorise la navigation parmi celles exécutées précédemment, donnant accès à des statistiques, ou encore la possibilité de revoir des résultats d’exécution. Enfin, l’onglet Account regroupe des informations relatives à la facturation, l’usage, et l’administration des utilisateurs, rôles et accès notamment.
La connexion à Snowflake par les applications tierces se fait via des connecteurs ODBC/JDBC, des connecteurs pour Python, Spark ou autres: il s’agit alors de requêter Snowflake comme n’importe quelle autre base de données relationnelles, tout en tirant parti de la puissance de calcul de l’infonuagique.
Cette impression « qu’il n’y en a pas dans tous les sens » prédomine lorsque l’on navigue dans l’interface graphique de Snowflake, et c’est plutôt agréable.
Scalabilité et élasticité : rien de plus facile
La simplicité ne doit toutefois pas se faire au détriment des fonctionnalités. C’est heureusement un compromis que Snowflake n’a pas fait!
L’un des principaux arguments d’une solution infonuagique est lié aux performances qu’elle offre. Qui n’a jamais en effet pesté durant le délai requis lorsqu’il voulait afficher un rapport en vue d’une réunion importante, ou alors devant un message d’erreur (timeout !). Lorsque l’on utilise une solution traditionnelle sur site, les ressources computationnelles sont celles du serveur, et ne sont pas facilement extensibles. Plus les utilisateurs sollicitent la puissance de la machine, et plus les requêtes sont mises en concurrence, et placées en file d’attente. Ainsi, au fur et à mesure que le nombre d’utilisateurs croît, que le scope de l’application augmente, plus les délais de réponse suivent cette même courbe. Il n’est pas aisé de changer de serveur, ou de rajouter de la puissance à ce dernier « à la demande », car cela demande d’ajouter physiquement du nouveau matériel, de le configurer, etc…
Dans une offre infonuagique telle que Snowflake, on peut à la fois tirer parti de la scalabilité et de l’élasticité. La scalabilité est le fait de pouvoir augmenter la puissance ou le nombre de serveurs qui traiteront les demandes concurrentes des utilisateurs. Au fur et à mesure que l’auditoire augmente, on a la possibilité de faire suivre la capacité computationnelle pour absorber cette augmentation de charge. L’élasticité quant à elle permet une adaptation selon la charge de travail. Ainsi, lors de pics d’utilisation, la puissance peut être augmentée automatiquement, et lorsque l’utilisation redevient normale, le cloud libère les ressources supplémentaires pour réduire les coûts.
Là où se distingue Snowflake, c’est dans la facilité de gérer la scalabilité par le biais des entrepôts virtuels. Dans Snowflake, au lieu de parler de fréquence d’horloge, de nombre de threads, ou de quantité de mémoire vive, on parle de taille. Cela s’apparente à des tailles de tee-shirt (de X-Small à 4X-Large). Derrière ceci, se cache en réalité un nombre de serveurs (ou de cœurs) qui traiteront les demandes (XS : 1 serveur, jusqu’à 4XL : 128 serveurs). Mais tout cela est transparent pour l’utilisateur, il a juste à savoir que s’il lui faut plus de puissance, il suffit d’augmenter la taille de l’entrepôt, soit via l’interface Snowflake, ou via une simple commande SQL : aussi simple que de changer de tee-shirt !
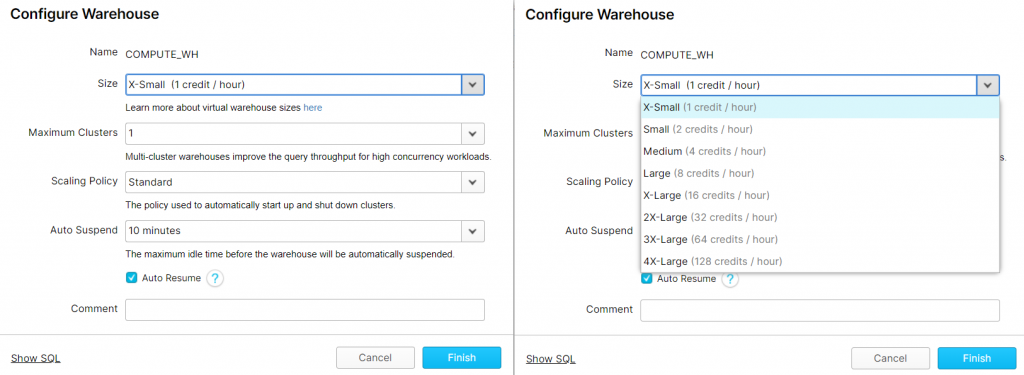
L’élasticité est quant à elle gérée de 2 manières distinctes. On a la possibilité d’arrêter ou de relancer automatiquement les Virtual Warehouse (via les options auto-suspend et auto-resume), mais également de gérer dynamiquement le multi-cluster (avec Snowflake edition entreprise au minimum). Cela permet de lancer plusieurs traitements en parallèle lorsque la demande se fait sentir (nombre d’utilisateurs ou de requêtes grandissant). La puissance augmente lorsque nécessaire, pour rebaisser lorsque le pic de charge diminue, afin de préserver les coûts.
Administration Snowflake: des DBA désœuvrés ?
Lorsque l’on pense à des bases de données, on pense à un système complexe, que ce soit à son implémentation et à sa maintenance. Il s’agit d’un travail difficile, géré par un ou plusieurs spécialistes, dont les DBAs (data base administrators) font partie.
Parmi les tâches propres à un DBA dans un environnement traditionnel, on pensera à l’optimisation par la mise en place d’indexes. Or, les indexes sont totalement inexistants de l’environnement Snowflake! Son architecture met en avant la gestion de micro-partitions. Chaque table d’une base de données Snowflake est composée de centaine, voire de millions de micro-partitions. Snowflake stocke pour chacune d’elles des métadonnées (plage de valeur des différentes colonnes, nombre de valeurs distinctes, etc…) permettant d’élaguer granulairement de très grandes tables. Tout ceci est géré automatiquement par Snowflake. Si cela ne suffit pas (table de plusieurs térabytes, perte de performance avec le temps), il y a la possibilité de mettre en place des cluster keys. Oui, mais alors, a-t-on simplement troqué les indexes par des cluster keys ? Si tel était le cas, qu’est-ce que ça changerait alors ? Ce n’est pas le cas. Déjà, les cluster keys sont loin d’être systématiques et on peut très bien s’en passer. De plus, leur mise en place est des plus faciles : une simple commande SQL permet d’indiquer sur quelle colonne (ou ensemble de colonnes) on souhaite mettre une cluster key, et c’est terminé. Pas besoin de choisir un type de cluster key, il n’y en a qu’un, et pas besoin de les rafraîchir ou de recalculer des statistiques ou autre. Lorsque c’est en place, il n’y a plus rien à gérer!
Le DBA traditionnel s’occupe également de la sauvegarde, en prévision de sinistres ou de corruption de données. Même si cette tâche n’est pas totalement éliminée dans Snowflake, elle y est grandement simplifiée, dans la mesure où Snowflake propose une fonctionnalité Fail-Safe. Celle-ci sauvegarde automatiquement les données pendant 7 jours, dans 3 data centers de la région hébergeant les données de l’utilisateur.
La gestion de la sécurité, qu’elle soit physique ou réseau est facilitée par les fonctionnalités intégrées dans Snowflake. On pensera par exemple au chiffrement de bout en bout, l’authentification multifactorielle (MFA), la gestion d’une liste blanche ou noire d’adresse IP, ou un VPS (Virtual private Snowflake) optionnel.
La mise à jour logicielle du système est une tâche importante en administration de BDs: là encore, elle est rendue obsolète par la gestion des mises à jour automatiques et transparentes de l’environnement Snowflake.
Même si les tâches d’un DBA se trouvent profondément simplifiées, il faut tout de même noter qu’il reste certaines tâches administratives à considérer, malgré tout :
– Mise en œuvre des sauvegardes. Même s’il est vrai que les fonctionnalités Snowflake simplifient la tâche, il faut tout de même être capable de corriger des erreurs humaines en cas de corruption de données.
– Gestion des coûts. Cette tâche administrative est simplifiée par l’interface Snowflake. Mais il faut tout de même veiller à ce que les coûts restent maîtrisés. La facturation se faisant à la seconde, il est important de suspendre les entrepôts virtuels lorsqu’ils ne sont pas utilisés, de ne pas céder à la tentation de trop les provisionner (plus de puissance = plus de coûts). Il est important également de maîtriser le scope de données, toujours plus de données signifie toujours plus de stockage, de calculs, et donc une facture qui gonfle exponentiellement.
– Administration des utilisateurs. Cette tâche est toujours présente. Il faut être en mesure de déterminer des profils utilisateurs (les rôles), de correctement les attribuer selon le besoin de chacun.
Snowflake est donc une solution indéniablement simple par bien des aspects, ce qui permet de mieux se concentrer sur les aspects essentiels, à savoir les besoins métiers. Il faut garder à l’esprit que cela n’en reste qu’un outil, et que son apparente simplicité ne dispense ses utilisateurs d’une certaine rigueur. Il ne faudrait pas être tenté de faire rimer simplicité avec approximation.



