
Par Gaël Baudry, Conseiller principal, Analytique des données
Dans son précédent article, notre spécialiste Maxime Fargeot présentait l’API Snowpark de manière générale. Ici, je vais plancher sur un cas concret d’utilisation Snowpark dans Python, en m’appuyant sur le concept d’évaluation lazy, ou « paresseuse ». Je vais combiner certaines fonctionnalités de Snowpark pour écrire un exemple de code comparant des objets de bases de données (ex. tables, vues) selon deux axes :
1 – Structure
2 – Données
Avant d’entrer dans le vif du sujet, je rappelle certains concepts Snowpark.
Dataframes Snowpark
Un dataframe est un composant essentiel de Snowpark. Il permet de récupérer et de manipuler des données. Le dataframe est une structure de données à 2 dimensions, comme le serait un tableau ou une table. Cette structure peut être manipulée par une série de méthodes. Ce qui fait la force de Snowpark, c’est le fait qu’il évaluera ces méthodes de façon lazy. Cela signifie que Snowpark cherchera à minimiser les exécutions Snowflake, parce que c’est dans un warehouse Snowflake que Snowpark effectuera le gros du travail, ne manipulera et ne transférera les données que lorsqu’une action spécifique sera déclenchée. Le but est à la fois de profiter de la puissance de calcul offerte par Snowflake, plutôt que celle de la machine qui exécutera le code Python, mais aussi de minimiser les échanges. Ce n’est que lors de l’exécution de certaines méthodes clés comme collect() que la récupération des données sera effective.
Le code généré côté Snowflake correspond à un ensemble de commandes effectuées en Python.
En plus d’être performant, les dataframes Snowpark offrent une grande souplesse. Les données d’un dataframe peuvent provenir de diverses sources, pas nécessairement toutes dans Snowflake. On a également la possibilité de ne prendre qu’un échantillon de colonnes, de lignes, etc., et le tout est parfaitement programmable en mode fluent.
Exemple
Dans cet exemple, une série de méthodes Snowpark/Python sont chainées, et ce n’est qu’au moment de l’exécution de la méthode collect() qu’une requête manipulant et retournant les données est exécutée dans Snowflake.
Imaginons une table ONE_MILLION_EXAMPLE ayant 2 colonnes :
- NUMBER_VALUE de type numérique ;
- TEXT_VALUE de type varchar.
Cette table contient 1 million de lignes et ressemble à ceci :

Commentons l’extrait de code Snowpark suivant :

1 – Initialisation d’un dataframe sur la table ONE_MILLION_EXAMPLE. Aucune donnée n’est lue, manipulée ou transférée.
2 – Filtre sur les lignes pour lesquelles NUMBER_VALUES < 10. Aucune donnée n’est lue, manipulée ou transférée.
3 – Ajout d’une colonne NEW dans notre dataframe, résultant de la concaténation des colonnes NUMBER_VALUE et TEXT_VALUE. Aucune donnée n’est lue, manipulée ou transférée.
4 – Affichage du dataframe. Exécution effective dans Snowflake et transfert de données vers la machine exécutant le code.
Par opposition, un connecteur Python traditionnel aurait vraisemblablement :
1 – Transféré et chargé 1 million de lignes de données de Snowflake dans la mémoire de la machine exécutant le code Python.
2 – Filtré en mémoire 10 lignes parmi le million.
3 – Calculé et ajouté la colonne dérivée par concaténation.
4 – Affiché le résultat.
L’exécution de ce code Snowpark ne génère qu’une seule requête potentiellement gourmande pour Snowflake. Le temps d’exécution demeure optimal, puisqu’utilisant pleinement la puissance de calcul de Snowflake. C’est bien le principe de l’évaluation lazy qui est illustré ici :

Comparaison de structure
Pour créer une fonction permettant de comparer la structure de 2 dataframes, nous allons utiliser la propriété schema, laquelle représente la structure d’un dataframe.
Par exemple, prenons un dataframe df1 représentant la table suivante :

La directive df1.schema retournera un objet représentant la structure de la table comme suit :

La propriété fields de cet objet, elle, retourne la liste des éléments inclus dans cette structure. Par la suite, il suffit de manipuler cette liste à l’aide des nombreuses possibilités offertes par le langage Python.
Pour comparer 2 dataframes df1 et df2, on peut procéder ainsi :
- Recherche des éléments présents dans la liste df1.schema.fields mais pas dans la liste df2.schema.fields.
- Inversement, recherche des éléments présents dans la liste df2.schema.fields mais pas dans la liste df1.schema.fields.
Par exemple, imaginons les structures suivantes :
df1 :

df2 :

Les listes schema.fields respectives sont :
df1 :

df2 :

Par la suite, on peut dresser la liste des éléments présents dans df1 mais pas dans df2 et vice versa, pour obtenir :
![]()
La fonction Python suivante exploite cette idée :

Elle retourne la liste des différences trouvées entre les propriétés schema.fields des deux dataframes passés à l’appel.
Comparaison de données
Pour créer une fonction permettant de comparer les données contenues dans 2 dataframes, nous allons procéder selon la démarche suivante :
1 – Initialiser 2 dataframes à comparer.
2 – Établir s’ils sont comparables, c’est-à-dire s’ils ont une structure commune.
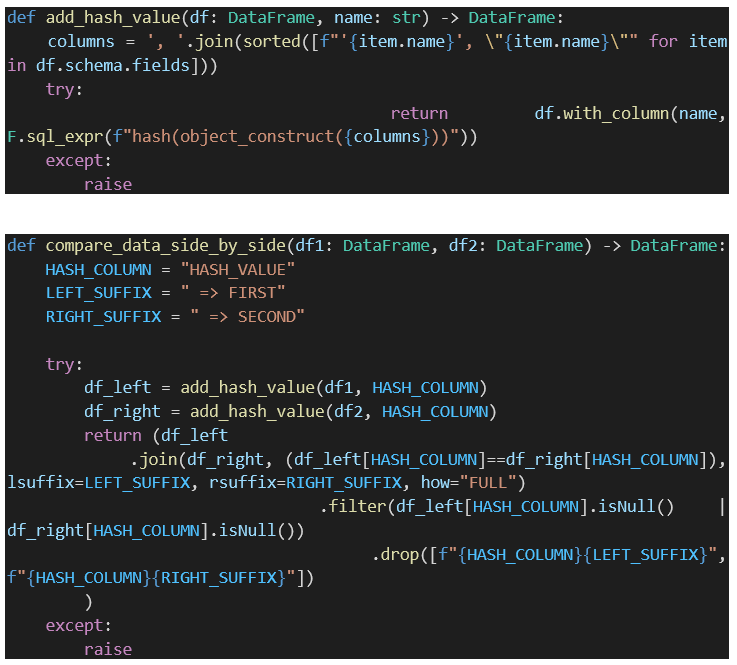
3 – Dans l’affirmative, comparer une à une chaque ligne contenue dans ces dataframes. Pour gagner en performance, plutôt que comparer les colonnes entre elles, nous allons le faire globalement à l’aide d’une fonction de hachage.
4 – Produire un troisième dataframe qui sera le résultat d’un full join entre les 2 dataframes initiaux, liés sur fonction de hachage. Le contenu de ce dataframe sera les lignes qui diffèrent entre les dataframes initiaux.
Par exemple, imaginons deux dataframes contenant les données suivantes :
df1 :

df2 :

Ces dataframes ont une structure commune, ce que l’emploi de la fonction Python introduite plus tôt confirmerait. On peut toutefois observer quelques différences au niveau des données :
- L’ordre des lignes n’est pas le même, ce qui n’est pas nécessairement signe d’une différence.
- Pour la ligne 3, la valeur de la colonne 3 est différente.
- La ligne 4 n’existe que dans df2.
Pour comparer ces données, nous allons employer la fonction Snowflake HASH, laquelle retourne une valeur de hachage numérique. En couplant à la fonction Snowflake OBJECT_CONSTRUCT, laquelle sérialise toutes les colonnes d’une ligne donnée, il est possible d’obtenir une signature unique pour chaque ligne de nos dataframes (cependant, pour assurer la validité de la signature, il faut veiller à ce que l’ordre des colonnes soient les mêmes).
Pour nos 2 dataframes précédents, générons donc une colonne HASH_VALUE comme suit :

Ce qui produit :
df1 :

df2 :

L’examen de ces 2 tableaux permet de constater que la colonne HASH_VALUE à elle seule suffit à déterminer les différences dans les données des 2 dataframes.
Finalement, en liant les 2 dataframes (augmentés de la colonne HASH_VALUE comme illustrés ci-dessus) par un full join sur leurs colonnes HASH_VALUE, on peut produire le dataframe suivant :
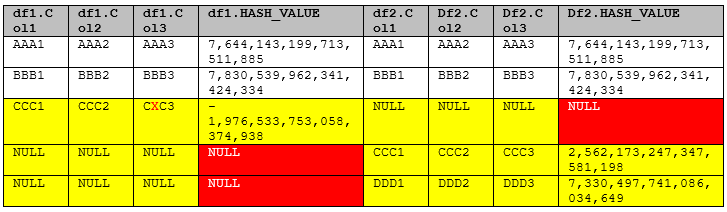
Compte tenu de l’emploi du full join :
- Les lignes identiques ont des valeurs identiques pour les colonnes issues de df1 et df2.
- Les lignes différentes sont repérées par certaines colonnes à NULL.
Les fonctions Python suivantes exploitent cette démarche :
Finalité Snowpark
Maintenant que toutes nos fonctions Python sont écrites, il ne reste plus qu’à les exploiter dans Snowpark.
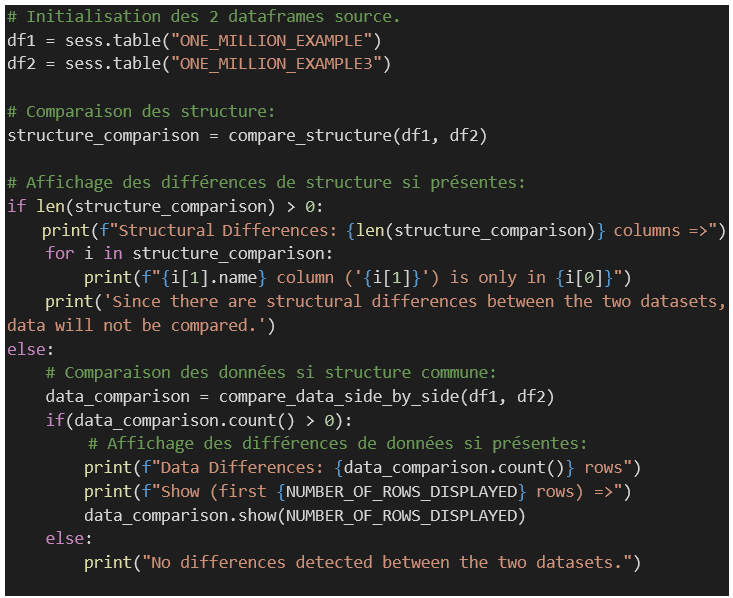
Si l’on suppose qu’un objet session Snowpark est déjà instancié, le code ci-dessous :
1 – Initialisera deux dataframes (selon des tables déjà existantes dans Snowflake mais d’autres possibilités sont offertes).
2 – Comparera les structures des dataframes.
3 – Comparera les données de ces derniers si comparables.
Le mot de la fin
S’il était utile de le démontrer, le code présenté ici reste relativement simple, et est très performant lorsqu’exécuté par l’entremise de Snowpark. Par opposition à s’il avait employé un connecteur Python classique, le nombre de ligne des tables n’a que peu d’incidence sur les performances. Dans l’exemple ci-dessus (tables de 1 million d’enregistrements) la requête générée a pris 49ms pour détecter des différences entre les données des 2 dataframes. Pas mal pour du code qui est exécuté localement, du moins en apparence. L’affichage des données peut quant à lui prendre une ou deux secondes, mais globalement, on peut dire que Snowpark glisse sur les données Snowflake!







