
Par Alexandre Lepage, Directeur principal, Entreprise numérique
En cette période de l’année où lecture et légèreté vont de pair, j’ai décidé d’être dans l’air du temps et d’écrire cet article à saveur estivale. Mon thème ludique? L’apprentissage machine.
En fait, le mathématicien en moi a eu l’occasion de renouer dernièrement avec une de ses anciennes amours : la plateforme computationnelle Wolfram Mathematica. Cette dernière en est maintenant à sa version 11.3 (la version 4.0 sortait à peine alors que je terminais mes études doctorales : ça ne nous rajeunit pas!). Histoire de m’amuser un peu (les loisirs, comme les goûts et les couleurs, ne se discutent pas), j’ai réalisé une petite expérience que je vous partage avec plaisir.
Comme vous pourrez le constater, les concepts utilisés sont très tendances puisqu’il s’agit de : science des données (ou data science), algorithmes, apprentissage machine (ou machine learning), apprentissage profond (ou deep learning) et même intelligence artificielle !
Mon expérience
Mathematica offre toute une panoplie de fonctions supportant l’apprentissage automatique, notamment avec la fonction Classify. Celle-ci permet de générer des fonctions de classification à usages divers. Pour rappel, la classification est cette opération qui étiquette des données, en les associant à des classes ou catégories prédéterminées. Il est possible d’entraîner la fonction Classify sur des jeux de données quelconques pour l’appliquer à des problèmes spécifiques mais pour les fins de mon expérience, je me suis contenté de l’instancier en la fonction de classification native NotablePerson.
L’idée ? Utiliser cette fonction de reconnaissance d’images pour trouver le sosie célèbre de chaque membre du comité de direction de Larochelle !
Afin d’illustrer l’élégance de Mathematica (un exercice similaire avec Python n’aurait guère été plus compliqué), notons que l’ensemble de mon expérience se résume d’abord à définir une petite fonction maison nommée notableIdentify comme suit

puis à lui soumettre les photos des membres du comité de direction. Pour chaque image, la fonction notableIdentify listera les 5 célébrités les plus probablement correspondantes ou ressemblantes (merci à l’exemple documenté par Wolfram pour l’inspiration).
Les résultats
Cher lecteur, comme je suis convaincu qu’à ce stade-ci seuls les résultats t’intéressent, les voici sans plus tarder.
Éric Larochelle, président
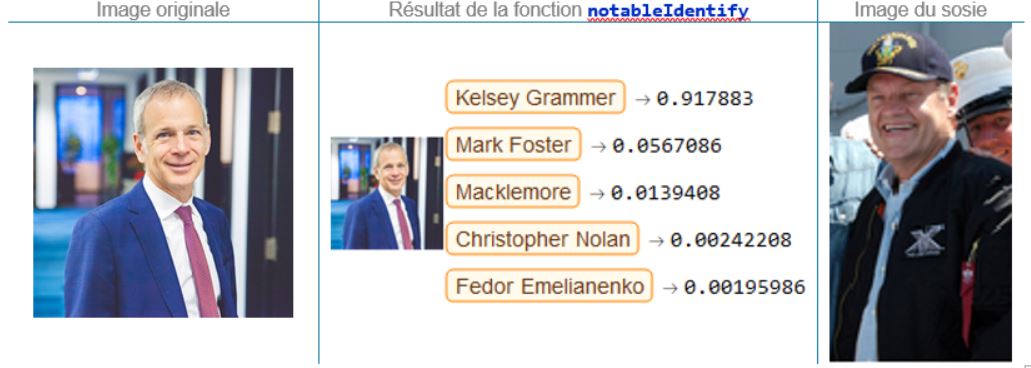
Avec une probabilité d’appartenance de près de 92%, Mathematica semble convaincu qu’Éric et Kelsey Grammer sont une et une seule personne : comme doppelgänger, on repassera !
Annie Arseneault, vice-présidente, Ventes
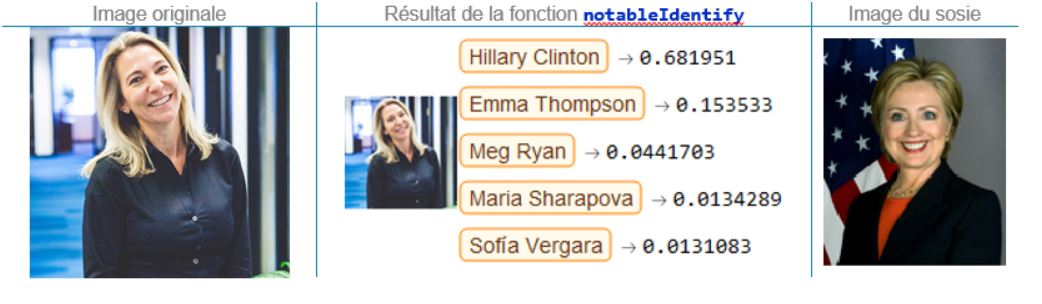
Les similarités entre Annie et Hillary Clinton sont bien visibles; mais quant à savoir si notre vice-présidente aux ventes l’aurait remporté contre Donald Trump en novembre 2016 !
Michel O. Côté, vice-président, Développement corporatif
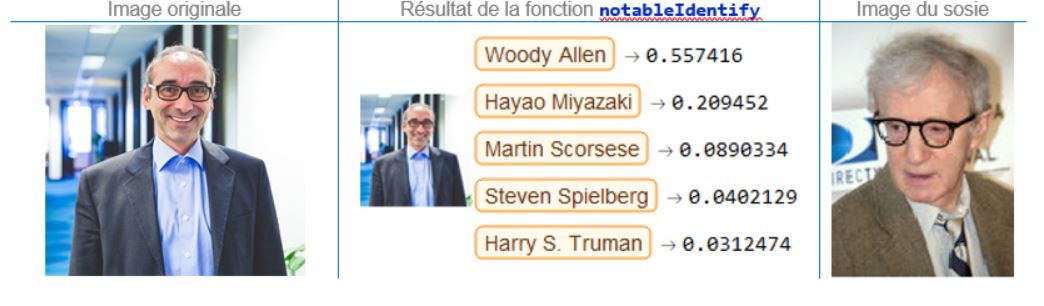
On peut apprécier la ressemblance, mais pauvre Michel : en cette époque du mouvement #MeToo (mouvement très sérieux au demeurant), ce n’est peut-être pas le bon moment d’être confondu avec Woody Allen.
Kiet Cuong, vice-président, Services-conseils

Hmmm. On croirait presque que la fonction employée effectue du profilage racial. Et à la place de Kiet, je préférerais de loin être identifié à Adam Sandler plutôt qu’à Mao Zedong ou à Kim Jong Un !
Annie Loiselle, vice-présidente, Attraction de talents
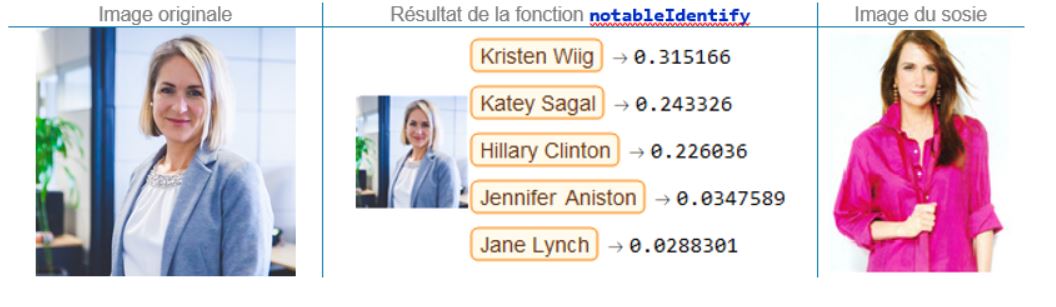
La vraisemblance n’est pas des plus grandes: à peine 31% ! Mais on peut croire à la ressemblance entre Annie et Kristen Wiig, surtout lorsqu’on peut espérer que cette dernière soit des plus sympathiques (c’est du moins ce que laissent envisager la plupart des rôles qu’elle joue).
Francine Marcoux, vice-présidente, Finances et administration

Je peux concevoir que Francine ait des airs de famille avec Sarah Palin; cependant, je ne peux m’imaginer un univers dans lequel Francine aurait été une figure de proue du Grand Old Party !
Éric Ladouceur, directeur principal, Analytique des données
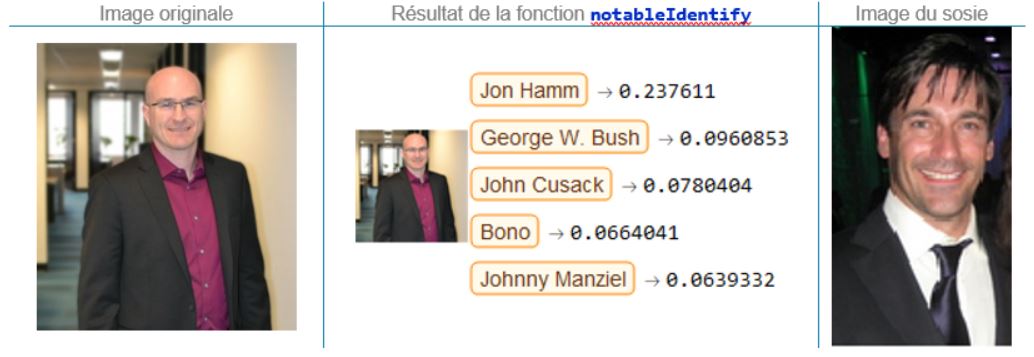
Le sourire y est, mais pas la chevelure! Normal : les similarités entre Éric et Jon Hamm sont plutôt faibles, ce que nous confirme une probabilité d’appartenance d’un peu moins de 24%.
Marie-José Lesage, directrice principale, Conseil en gestion & technologies
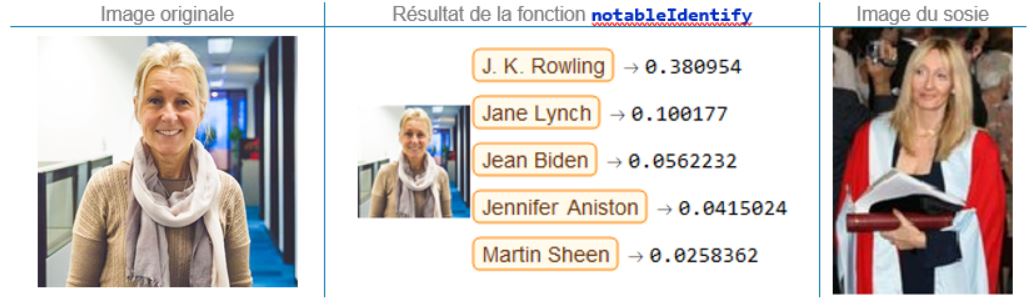
Même lorsqu’on sait que Marie-José a l’imagination débordante (et indubitablement la chevelure platine) de J.K. Rowling, on hésite à prétendre qu’elles se ressemblent comme deux gouttes d’eau.
Mathieu Moles, directeur principal, Analytique des données
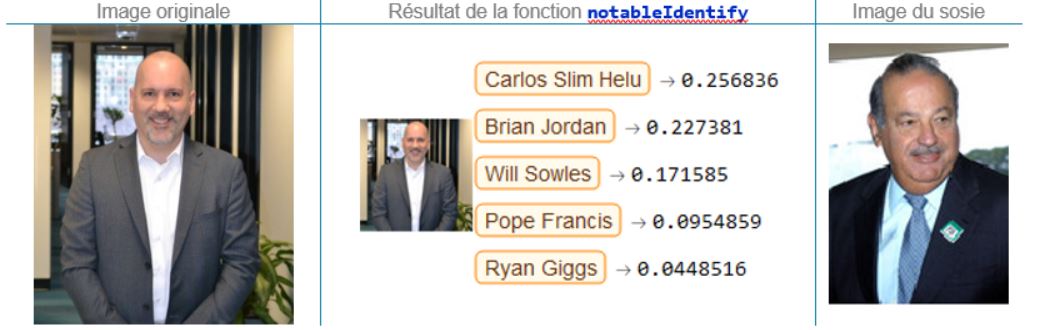
On peut reconnaître quelques points communs entre Mathieu et Carlos Slim Helu; malheureusement pour Mathieu, toute ressemblance s’arrête bien avant portefeuille et comptes en banque !
Renaud Chevrier, directeur principal, Québec
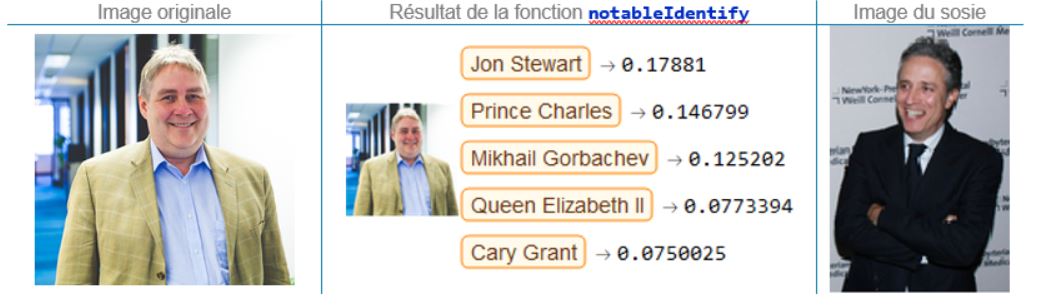
Avec la vraisemblance la plus basse de mon expérience, un peu moins de 18%, on se doute bien que Jon Stewart n’est pas le sosie de Renaud; c’est connu : Renaud ne ressemble à personne !
Bernard Séguin, directeur principal, Conseil stratégique
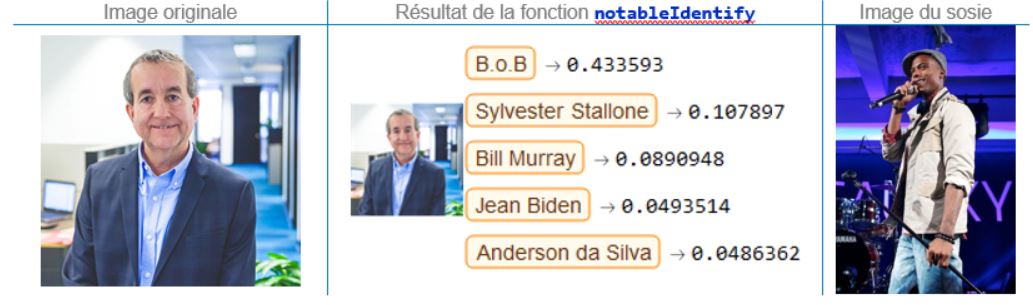
On oublie mon hypothèse de profilage racial avancée plus haut, puisque Bernard est associé à l’artiste hip-hop B.o.B.. Vas-y, slame Bernard !
Alexandre Lepage, directeur principal, Entreprise numérique
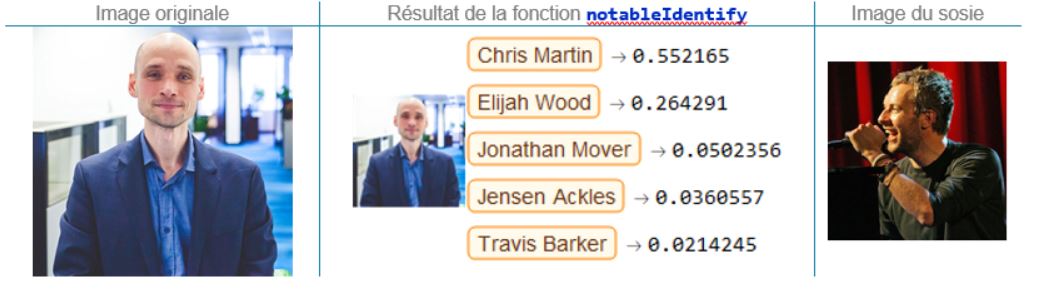
J’ai délibérément gardé bibi pour la fin. Oui, je ressemble en tout point à Chris Martin, le chanteur de Coldplay : même charisme, même talent. Et je l’affirme en toute humilité.
Quelques commentaires
Ô précieux lecteur, avant de soupirer de déception face à des résultats pas toujours concluants, de désespérer alors de voir un jour des véhicules autonomes engorger le (nouveau) Pont Champlain puis de crier ultimement à l’imposteur parce que tu réalises les quelques raccourcis logiques que j’ai empruntés, permet-moi quelques commentaires.
Tout d’abord, le métier d’analyste de données (rien à faire : « scientifique de données » sonne faux!) ne consiste pas à accepter bêtement les résultats d’un algorithme, mais bien de les interpréter. En considérant par exemple la probabilité d’appartenance, les plus grandes vraisemblances de mon expérience sont reproduites dans le diagramme suivant :
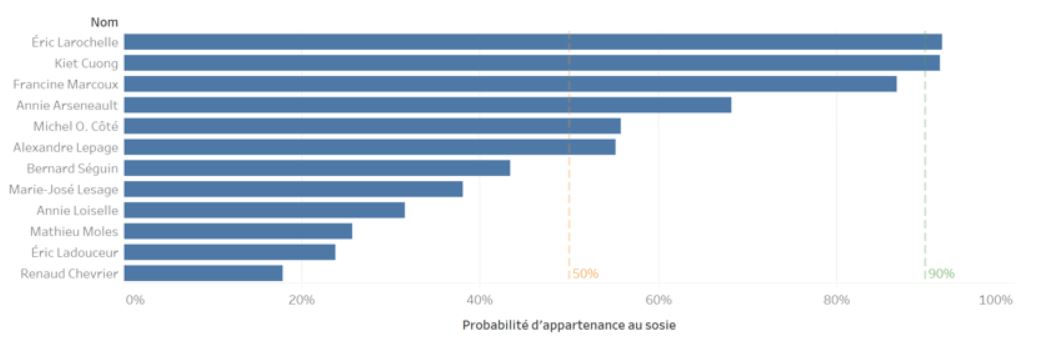
- Avec 6 cas sur 12 ayant une vraisemblance de moins de 50%, c’est la moitié de nos sosies qui sont fort probablement mal identifiés;
- Si on prétend qu’un seuil de vraisemblance de 90% serait idéalement requis pour conclure au sosie correctement identifié (à dire vrai, dans un contexte hypothétique de décision d’affaires supportée par apprentissage automatique, quel serait le seuil minimal acceptable?) : est-ce qu’Éric Larochelle et Kiet Cuong, les 2 seuls cas respectant ce critère, ressemblent tant que ça à Kelsey Grammer et Mao Zedong respectivement? Pourquoi ma fonction a-t-elle fait ces propositions.
L’analyste de données a également la responsabilité de choisir la méthode adéquate pour une tâche donnée : une classification dans le cas de mon expérience. Or, la fonction de classification NotablePerson que j’ai employée sert à étiqueter des images… de célébrités… pas des images des membres du comité de direction de Larochelle, aussi illustres soient-ils ou elles! Ainsi, ma fonction maison nommée notableIdentify est surtout pertinente, dans la mesure où je lui passe en paramètre l’image d’une personnalité.
Par exemple :
Chris Martin, chanteur, Coldplay
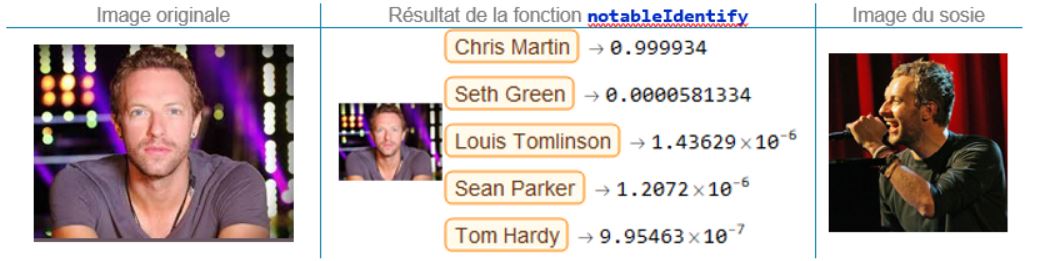
Avec une probabilité d’appartenance qui frôle les 100%, on ne rit plus et on tombe en pâmoison devant la perspicacité de Mathematica (ou devant Chris Martin, c’est selon).
En trichant et présumant qu’un membre donné du comité de direction de Larochelle ressemble bel et bien à une certaine célébrité, on peut certainement rire un peu. Mais comme je demande à ma fonction d’étiqueter, elle étiquettera, peu importe, l’image passée en paramètre et la vraisemblance du résultat (par défaut).
Pour preuve :
Une rose
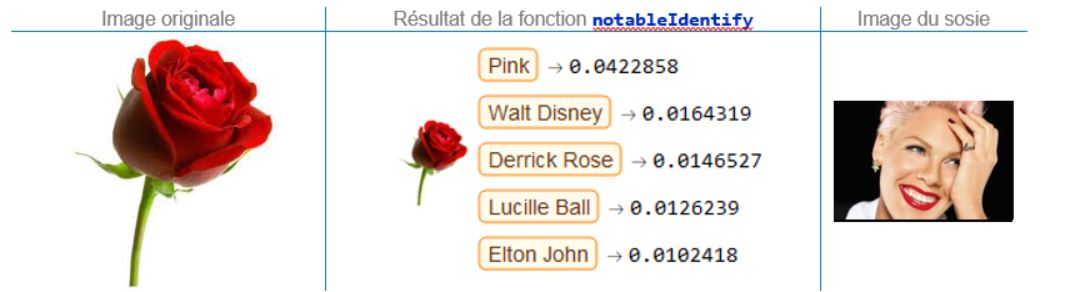
D’accord, une probabilité d’appartenance d’à peine 4% n’impressionne personne. Mais il faut avouer qu’il y a quelque chose de poétique à identifier la chanteuse P!nk comme sosie… d’une rose… Et que dire de la suggestion surréaliste de Derrick Rose des Timberwolves du Minnesota, aussi improbable soit-elle !?!
Finalement, l’analyste de données se doit de connaître quelques détails propres à l’algorithme choisi, notamment les données employées et au moment de l’apprentissage (dans un contexte d’apprentissage supervisé comme pour mon expérience) et au moment du test. Pour être tout à fait franc, je n’ai pas cherché à en savoir plus sur les images employées par Mathematica pour entraîner la fonction de classification NotablePerson. Mais je sais que cette dernière contient 1,001 classes (célébrités), pas une de plus, pas une de moins, avec un biais documenté envers les personnalités américaines. Il ne faut alors pas s’étonner que les sosies identifiés soient pour beaucoup étatsuniens.
Quant aux données utilisées pour mon expérience, elles sont ce qu’elles sont. La question qui demeure : ces images sont-elles représentatives des membres du comité de direction de Larochelle ?
Conclusion
Ma première intention avec cet article est bel et bien de proposer une lecture estivale, légère et amusante.
Ma seconde intention, plus professionnelle, est d’illustrer avec ma petite expérience une réalité indéniable de l’artisanat que constitue l’analytique avancée. En effet, pour plusieurs cas d’usage, la clé du succès dépend davantage de l’artisan (l’analyste) et de sa matière première (les données) que de l’outil (l’algorithme).
Alors, ai-je réussi mon coup cher lecteur ? N’hésite pas à me répondre en laissant un commentaire.
Sur ce, bon été !
