
Par Aurélie Mazereau, Directrice, Analytiques des données
Il y a encore quelques dizaines d’années, l’étude de la biodiversité était laissée à la seule responsabilité des scientifiques qui identifiaient une zone de terre représentative pour leur étude, y dénombraient les espèces présentes et extrapolaient des conclusions en utilisant des techniques statistiques. Cette méthode de travail, bien qu’efficace, demandait beaucoup d’efforts et ne pouvait fonctionner qu’à un niveau local (1).
Depuis une quinzaine d’année, la multiplication des données ainsi que les avancées dans le domaine du stockage computationnel ont rendu possible un nouvel essor des réseaux de neurones. L’utilisation de ces derniers dans des projets d’observation et d’identification du vivant a ensuite permis d’augmenter la rapidité, la précision, et l’étendue des études réalisées.
Qu’est-ce qu’un réseau de neurones?
Les réseaux de neurones, inspirés du fonctionnement du cerveau humain, sont des algorithmes capables de modifier leurs configurations d’eux-mêmes afin de traiter des informations avec les meilleurs résultats possibles.
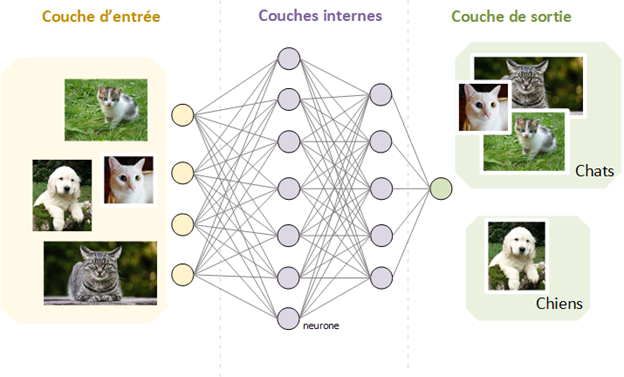
Un réseau de neurones est organisé en différentes couches de nœuds de traitement (ou neurones) interconnectés les uns aux autres, et contenant chacun une série d’informations permettant le calcul du résultat final. Selon le modèle utilisé, un nœud pourra contenir l’historique des données qu’il a déjà traitées, les règles programmées lors de la création initiale du réseau, ou les règles qu’il aura créées lui-même.
La première couche constitue le point d’entrée de la machine et reçoit les informations à traiter, puis chaque couche successive reçoit les données de la couche précédente. La dernière couche produit le résultat final (2). Le nombre de couches intermédiaires est variable d’un modèle à l’autre: plus il y a de couches, plus le réseau est qualifié de profond (deep learning).
La force des réseaux de neurones réside dans leur capacité à mettre en place et faire évoluer leurs propres règles de calcul. Pour laisser la machine définir ses propres règles, la méthode la plus répandue consiste à utiliser une phase d’apprentissage: au cours de cette phase, un jeu de données dont on connait le résultat est fourni à la machine. Le modèle en apprentissage traite le jeu de données et compare les résultats qu’il a calculés avec les résultats attendus. À chaque erreur de résultat, les règles internes des neurones s’ajustent d’elles-mêmes pour augmenter le taux de succès.
Une fois la phase d’apprentissage terminée, le réseau de neurones est prêt à être utilisé avec des données dont le résultat n’est pas connu par avance.
Nous pouvons détailler l’exemple d’un réseau de neurones utilisé pour distinguer des photos de chats et de chiens :
– La couche d’entrée du réseau reçoit un jeu de photos non identifiées.
– Les photos traversent le réseau de neurones en se déplaçant d’un neurone à l’autre. Chaque neurone réalise une opération sur les données qui le traversent et dont la nature n’a pas été imposée par le créateur.
– La couche de sortie fournit une classification des photos soumises.
Utilisation des réseaux de neurones dans les projets d’observation du vivant
Les réseaux de neurones sont particulièrement efficaces pour identifier des formes, visages, ou animaux sur des photographies. C’est pourquoi ils sont de plus en plus souvent utilisés dans les projets d’étude du vivant.
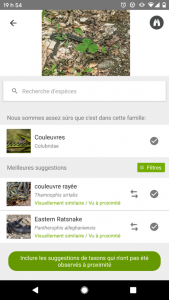
L’application INaturalist est un exemple de ce type d’utilisations. Elle a été lancée en 2008 par des étudiants de l’université de Californie comme un projet collaboratif d’identification et de recensement du vivant. Lors de sa création, le projet n’utilisait pas d’algorithme de machine learning: un utilisateur téléchargeait simplement une photo sur l’application, et la communauté (incluant des experts bénévoles) l’aidait à identifier l’espèce prise en photo.
Avec le succès croissant de l’application, le temps nécessaire à la communauté pour identifier une photo a grandi, et le besoin de mettre en place des suggestions d’identifications automatiques a émergé.
Pour ce faire, en 2017, l’équipe a développé un réseau de neurones et l’a entraîné sur un jeu de 4 millions de photos (3). Depuis la mise en service de cette intelligence artificielle, un utilisateur reçoit des suggestions d’identification des espèces présentes sur les photos qu’il soumet dans l’application.
Depuis 2017, le modèle du réseau de neurones est régulièrement mis à jour en même temps que la communauté continue de s’agrandir. Si bien que lors de la dernière mise à jour en octobre 2021, le modèle a été entrainé sur un jeu de 25 millions de photos (4).
Les réseaux de neurones, en apportant de nouvelles méthodes d’identification et de recensement automatique du vivant, ont permis d’augmenter considérablement la taille des jeux de données à disposition de la communauté scientifique. Ces données forment un formidable bassin d’informations pouvant être exploitées pour limiter le développement des espèces invasives, protéger les espèces en danger, prédire les variations de population d’un écosystème, etc.., comme dans le cadre du projet «Cambria’s invasive weed». Cette initiative permet aux habitants de la région de Cambria (côte ouest des États-Unis) de rapporter la présence de plantes invasives via l’application INaturalist. Les données ainsi récoltées sont utilisées par les autorités pour mieux suivre l’évolution des plantes invasives dans la région et mettre en place des mesures de prévention adaptées pour limiter leur développement.
Sources:
(1) https://medium.com/mlearning-ai/measuring-biodiversity-how-machine-learning-can-help-achieve-impact-goals-7ceb38e5aba
(2) Que signifie Réseau de neurones artificiels (RNA)? – Definition IT de Whatis.fr (techtarget.com)
(3) https://www.i-programmer.info/news/105-artificial-intelligence/10848-inaturalist.html/
(4) Journal de iNaturalist · iNaturalist


