
Par Radhwan Jouini, conseiller, Développement et technologies
Le Data Vault est une méthode d’organisation des données qui, entre autres choses, sépare les informations structurelles, telles que l’identificateur unique d’une table ou les relations des clés étrangères, des attributs descriptifs ou contextuels. Il a été créé pour permettre l’entreposage et la vérification des données historiques, favoriser le chargement parallèle des données et aider les organisations ayant plusieurs systèmes sources en permettant une évolution de leurs solutions de données sans trop avoir à les refondre. Le Data Vault offre de la souplesse et s’adapte facilement, ce qui en fait un outil de choix pour les entreprises en pleine croissance qui ont fréquemment à composer avec de nombreux remaniements de leur solution de données.
Contexte
Les premières mises en œuvre du Data Vault sont apparues dans les années 2000, mais cette méthode a été développée par Dan Linstedt au cours des années 1990.
Parmi les principaux avantages du Data Vault, notons :
- Il offre des options intéressantes aux organisations qui doivent exécuter des projets Data Warehouse agiles où l’évolutivité, l’intégration, la rapidité de développement et l’orientation métier sont importantes. En gardant à l’esprit l’échelle de l’entreprise, il adopte et améliore le meilleur de la conception traditionnelle de l’entrepôt de données.
- Il est techniquement indépendant et peut être utilisé avec la plupart des produits Data Warehousing et Business Intelligence.
Modélisation du Data Vault
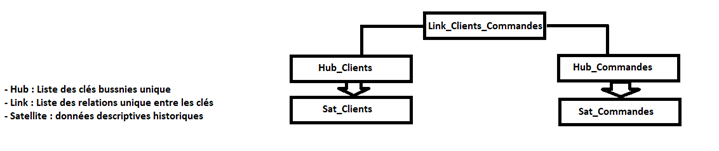
À la base, un modèle de Data Vault est représenté par trois types de tables :
– Les tables de type Hub : contiennent toutes les clés naturelles pour un sujet.
– Les tables de type Link : suivent toutes les associations entre les hubs.
– Les tables de type Satellite : contiennent tous les attributs descriptifs ou contextuels associés à un Hub ou un Link et les actualisent à mesure qu’ils évoluent.
Par exemple :
La valeur ajoutée du Data Vault
Le Data Vault se veut agile. Ainsi, il se développe de façon incrémentale et impose des migrations vers l’avant uniquement, c’est-à-dire que la structure d’une table dans une Data Vault n’est jamais changée. Plutôt :
– Lorsque de nouveaux systèmes fournissent des données complémentaires à celles déjà contenues dans le Data Vault, ils sont pris en charge par de nouveaux satellites ou links.
– Lorsque des attributs sont ajoutés dans une table source, un nouveau satellite est créé dans le Data Vault pour les accueillir. Il n’est pas nécessaire que cet ajout s’applique à toutes les données historiques déjà conservées.
– Lorsque de nouvelles relations sont présentes dans les sources, elles sont simplement insérées dans des links déjà existants ou dans de nouveaux links.
– De même, lorsque des relations sont changeantes ou supprimées, les liens correspondants dans le Data Vault sont expirés.
Il n’est donc pas nécessaire dans un Data Vault de modifier un schéma existant. Il suffit de tenir compte des nouveaux changements et de les prendre en charge à l’aide de nouveaux objets.
De plus, le Data Vault propose nativement des fonctionnalités en support à la gouvernance des données. Par exemple :
– Parce qu’aucune donnée n’est effacée d’un Data Vault, il favorise audits et vérifications.
– De même, aucune donnée n’est mise à jour dans un Data Vault. Lorsqu’un attribut est mis à jour dans la source, un nouvel enregistrement est créé dans le Data Vault. Les versions historiques des données sont ainsi toutes disponibles et accessibles.
– Le Data Vault est riche en métadonnées. Les temps de chargement et l’information de la source sont requis pour chaque ligne de données.
Tous ces mécanismes, et de nombreux autres, facilitent la traçabilité et la vérifiabilité des données vérification. Des atouts majeurs dans des contextes fortement réglementés.
Positionnement du Data Vault
Data Lake, Data Warehouse et Data Vault ne sont pas mutuellement exclusifs mais plutôt complémentaires :
– Data Lake : Dépôt centralisé conçu pour le stockage, l’archivage et la sécurisation de grands volumes de données structurées, semi-structurées et non structurées dans un format natif. Le Data Lake peut très bien jouer le même rôle que le « Persistent Staging Layer » visible dans bien des implémentations Data Vault.
– Data Warehouse : Dépôt spécialisé conçu pour le stockage, la persistance et l’intégration de données de sources diverses en support aux décisions d’affaires. Les données sources peuvent tout à fait être d’abord déposées dans un Data Lake avant d’être chargées dans le Data Warehouse, transformées ou non.
– Data Vault : La méthode Data Vault peut très bien être employée pour construire un Data Warehouse. Même si a priori le Data Vault accueille les données « bonnes » ou « mauvaises », c’est-à-dire qui ne respectent pas les règles d’affaires ou qui ne sont pas préparées pour une analyse particulière, il peut très bien prendre en charge ces dernières à l’aide de vues ou de constructions plus pérennes comme des « Point in Time », des « Bridges » et des Data Marts.
Les données du Data Warehouse peuvent ensuite être consommées, analysées et visualisées directement ou par l’entremise de modèles dimensionnels (schémas en étoile), cubes ou autres.
Résumé
En conclusion, la méthode Data Vault offre des solutions à des problèmes fréquents rencontrés dans des environnements d’exploitation changeants et peut réduire la complexité d’évolution d’une plateforme de données.
Efficace, efficient, facile à concevoir, construire, remplir et éditer, parce que systématique, le Data Vault est très populaire non sans raison.


