
Par Jean-Milou Pierre, directeur principal, Architecte de données
L’architecture médaillon : une approche structurée pour gérer les données
Dans un monde où les volumes de données explosent, il devient primordial d’adopter des architectures permettant une gestion efficace et optimisée. L’architecture médaillon s’impose comme une référence dans les lacs de données, facilitant l’organisation et la transformation progressive des données. Décomposée en trois couches (Bronze, Silver, Gold), elle permet d’assurer une meilleure qualité et fiabilité des informations tout en optimisant leur exploitation.
Qu’est-ce que l’architecture médaillon ?
L’architecture médaillon repose sur une approche en couches, permettant une gestion progressive des données :
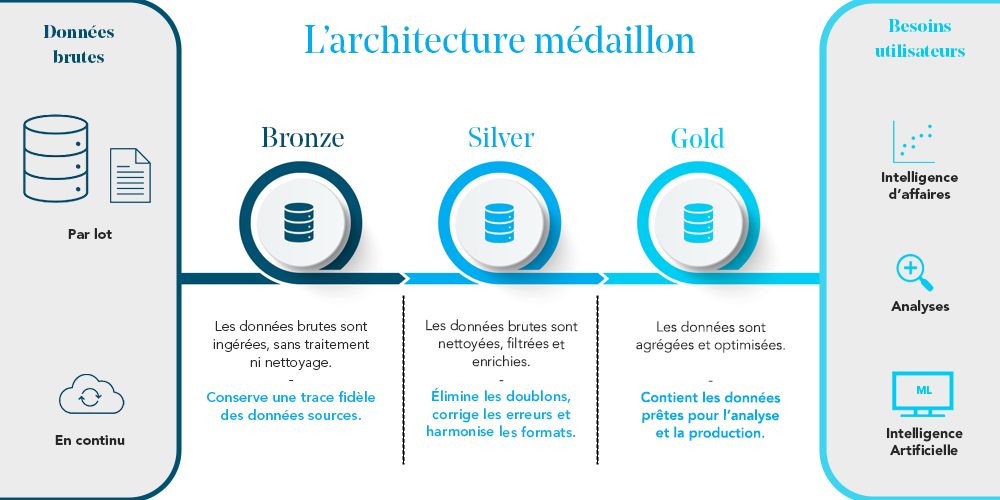
- Bronze : cette première couche stocke les données brutes telles qu’elles sont ingérées, sans traitement ni nettoyage. Elle sert principalement à conserver une trace fidèle des données sources ;
- Silver : les données sont nettoyées, filtrées et enrichies. Cette couche permet d’éliminer les doublons, de corriger les erreurs et d’harmoniser les formats ;
- Gold : la dernière couche contient des données prêtes pour l’analyse et la production. Elles sont agrégées et optimisées pour répondre aux besoins des utilisateurs métier.
Pourquoi adopter l’architecture médaillon ?
L’architecture médaillon est particulièrement adaptée aux entreprises manipulant de grandes quantités de données et nécessitant une structuration rigoureuse. Que ce soit pour des analyses avancées, l’intelligence artificielle ou la gouvernance des données, cette approche permet d’allier flexibilité et performance.
Toutefois, il est essentiel de bien évaluer les besoins avant d’opter pour ce modèle. Une bonne architecture ne doit pas complexifier inutilement les processus, mais au contraire faciliter l’accès aux données et leur exploitation.
Les avantages de l’architecture médaillon
- Qualité et fiabilité des données : grâce aux transformations progressives, les données gagnent en précision et en pertinence au fil des étapes ;
- Scalabilité : cette architecture est pensée pour les environnements big data, permettant de traiter d’importants volumes de données sans perte de performance ;
- Flexibilité : chaque couche répond à un besoin spécifique, offrant aux utilisateurs des niveaux de détail adaptés ;
- Traçabilité et gouvernance : les données étant stockées à chaque étape, il est plus facile d’assurer un suivi, un audit et une conformité réglementaire ;
- Optimisation des performances : plutôt que d’effectuer des transformations complexes en temps réel, celles-ci sont réalisées en amont, garantissant des temps de réponse rapides.
Quelques points à considérer
- Complexité de mise en place : implémenter cette architecture nécessite une bonne maîtrise des infrastructures de données et des pipelines de transformation ;
- Coût de stockage : bien que la multiplication des copies de données puisse augmenter les coûts, le stockage est aujourd’hui plus abordable grâce aux solutions cloud évolutives ;
- Latence dans l’exploitation des données : le passage par plusieurs étapes implique un délai avant que les données ne soient disponibles pour l’analyse ;
- Redondance des données : chaque couche contenant une version différente des mêmes données, l’espace de stockage requis est plus conséquent ;
- Nécessité d’automatisation : pour garantir la fluidité du processus, il est souvent indispensable de mettre en place des pipelines de transformation automatisés.
Databricks et l’architecture médaillon
Databricks, une plateforme d’analyse unifiée basée sur Apache Spark, adhère pleinement à l’architecture médaillon à travers son framework Delta Lake.
- Gestion des couches : Delta Lake permet de structurer les données selon les niveaux Bronze, Silver et Gold, offrant un suivi clair de l’évolution des données ;
- Optimisation des performances : grâce aux fonctionnalités de stockage transactionnel, les requêtes sont plus rapides et la gestion des mises à jour est simplifiée ;
- Fiabilité et gouvernance : les fonctionnalités comme le Time Travel et l’ACID compliance garantissent une meilleure intégrité des données ;
- Réduction des coûts : en exploitant un stockage cloud efficace et des mécanismes d’optimisation comme le Z-Ordering et le data skipping, Databricks limite les coûts d’exploitation.
Z-Ordering et Data Skipping : optimisations clés
- Z-Ordering : cette technique d’optimisation regroupe les données similaires dans des blocs de stockage. Elle réorganise physiquement les données en fonction d’une colonne clé (ex. : date, ID client) pour accélérer les recherches et les filtrages. Cela permet d’améliorer les performances des requêtes en limitant le nombre de fichiers scannés ;
- Data Skipping : Cette optimisation permet d’éviter de scanner des fichiers inutiles en conservant des métadonnées décrivant la plage de valeurs contenue dans chaque fichier. Lorsqu’une requête filtre les données sur une plage spécifique, Delta Lake peut ignorer les fichiers qui ne contiennent pas ces valeurs, réduisant ainsi le temps de traitement.
L’intégration de l’architecture médaillon avec Databricks permet donc d’exploiter pleinement le potentiel du big data et de l’intelligence artificielle, tout en garantissant une gouvernance robuste des données.
Pour conclure, l’architecture médaillon est un modèle robuste et efficace pour structurer les données dans un lac de données. Avec l’adoption de technologies comme Databricks et Delta Lake, elle garantit qualité, gouvernance et scalabilité. Son adoption doit être réfléchie en fonction des besoins spécifiques de l’entreprise. Une mise en place bien planifiée permettra d’en tirer le meilleur parti et d’optimiser la gestion des données pour une exploitation plus efficace et stratégique.